使用 CatBoost 实现分类特征的 SHAP
避免对分类特征的 SHAP 值进行后处理
结合 [[CatBoost]] 和 [[SHAP]] 可以提供强大的洞察力。特别是当你使用分类特征时。CatBoost 处理这些特征的方式使你更容易理解使用 SHAP 的模型。
对于其他建模包,我们需要先使用 One-Hot 编码转换分类特征。问题是每个二进制变量都有自己的 SHAP 值。这使得很难看到原始分类特征的整体贡献。
在 分类特征的 SHAP 中,我们探讨了一种解决方案。它涉及深入研究 SHAP 对象并手动添加各个 SHAP 值。这可能很乏味!作为替代方案,我们可以使用 CatBoost。
CatBoost 是一个梯度提升库。与其他库相比,它的一大优势是它可以处理非数值特征。无需转换分类特征即可使用它们。这意味着 CatBoost 模型的 SHAP 值易于解释。每个分类特征只有一个 SHAP 值。
我们将: - 计算并解释 CatBoost 模型的 SHAP 值 - 应用 SHAP 聚合 ——我们将看到,在理解分类特征的关系时,它们的作用是有限的 - 为了解决这个限制,将为单个特征创建一个蜂群图 。 - 在此过程中,我们将介绍用于获取这些结果的 [Python 代码]1。
你可能会喜欢有关此主题。如果你想了解更多,请查看我的 SHAP 课程。
数据集
对于此分析,我们将使用与之前相同的数据集。这是一个蘑菇分类数据集。你可以在 图 1 中看到此数据集的快照。目标变量是蘑菇的 类别。 也就是说,蘑菇是有毒 (p) 还是可食用 (e)。你可以在 [UCI 的 MLR]2 中找到此数据集。
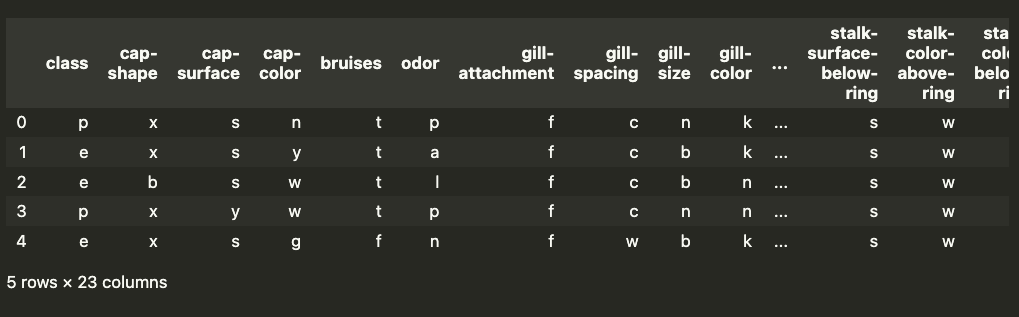
对于模型特征,我们有 22 个分类特征。对于每个特征,类别都用一个字母表示。例如, odor 有 9 个独特的类别 - 杏仁 (a)、茴香 (l)、杂酚油 (c)、鱼腥味 (y)、恶臭 (f)、霉味 (m)、无味 (n)、辛辣 (p)、辛辣 (s)。这就是蘑菇的气味。
建模
我们将向你介绍用于分析此数据集的代码,你可以在 [GitHub]3 上找到完整的脚本。首先,我们将使用下面的 Python 包。我们有一些用于处理和可视化数据的常用包(第 1-5 行)。我们使用 CatBoostClassifier 进行建模(第 7 行)。最后,我们使用 shap 来了解我们的模型如何工作(第 9 行)。确保你已安装所有这些包。
1 | |
我们导入数据集(第 2 行)。我们需要一个数值目标变量,因此我们通过设置
toxicous = 1 和 edible = 0(第 6
行)对其进行转换。我们还获得了分类特征(第 7
行)。在上一篇文章的这一点上,我们需要转换这些特征。使用
CatBoost,我们可以按原样使用它们。
1 | |
在下面训练模型时,你可以看到这一点(第 7
行)。我们传递非数值特征(X)、目标变量(y)和表示特征是分类的列表(
cat_features )。我们所有的特征都是分类的。这意味着
cat_features 是一个从 0 到 21 的数字列表。最后,分类器由 20
棵树组成,每棵树的最大深度为 3。它在训练集上的准确率为 98.7%。
1 | |
SHAP 图
现在我们可以继续了解我们的模型是如何做出这些预测的。如果你不熟悉 SHAP 或 Python 包,我建议你阅读下文章Python 中的 SHAP 简介。我们深入探讨了如何解释 SHAP 值。我们还探讨了本文中使用的一些聚合。
瀑布图
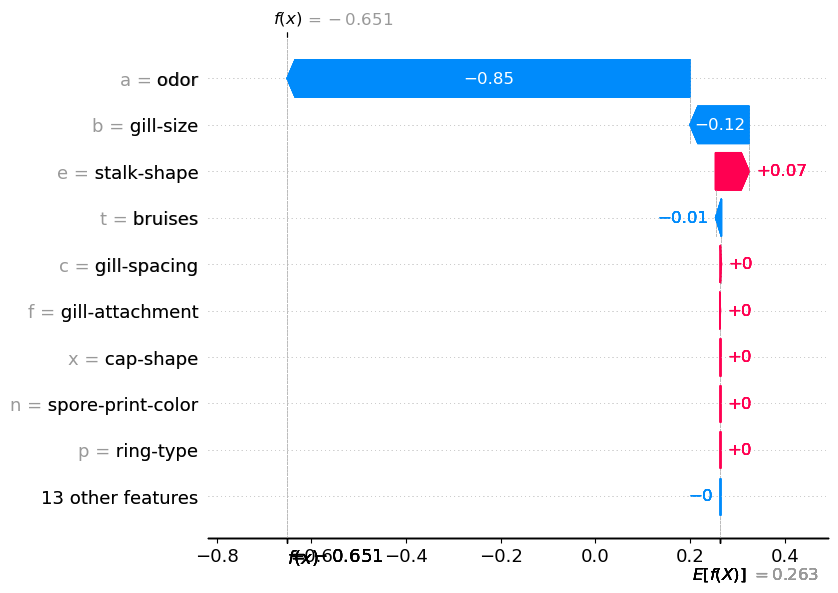
我们首先计算 SHAP 值(第 2-3 行)。然后,我们使用瀑布图(第 6 行)将第一个预测的 SHAP 值可视化。你可以在图 2 中看到此图。这告诉我们每个分类特征值对预测的贡献。例如,我们可以看到这种蘑菇有杏仁(a)的气味。这使对数几率降低了0.85。换句话说,它降低了蘑菇有毒的可能性。
1 | |
从上图中,很容易看出每个特征的贡献。相比之下,我们在图 3 中有一个瀑布图。如前所述,这是在上一篇文章中创建的。为了对分类特征进行建模,我们首先使用 One-Hot 编码对它们进行转换。这意味着每个二进制特征都有自己的 SHAP 值。例如,气味将有 9 个 SHAP 值。每个独特类别都有一个。因此,很难理解气味对预测的整体贡献。
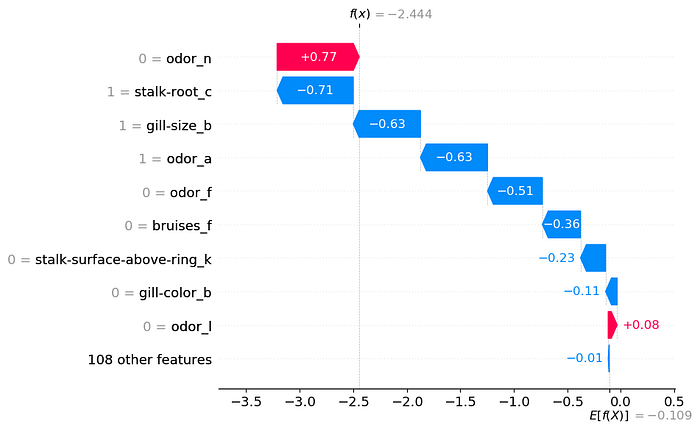
我们能够利用图 3 中的 SHAP 值来创建类似于图 2 的图。这样,每个分类特征就只有一个 SHAP 值。为此,我们需要通过将一个分类特征的所有值加在一起来“后处理” SHAP 值。不幸的是,没有直接的方法可以做到这一点。我们需要自己手动更新 SHAP 值对象。我们已经看到,通过使用 CatBoost,可以避免这个过程。
绝对平均 SHAP
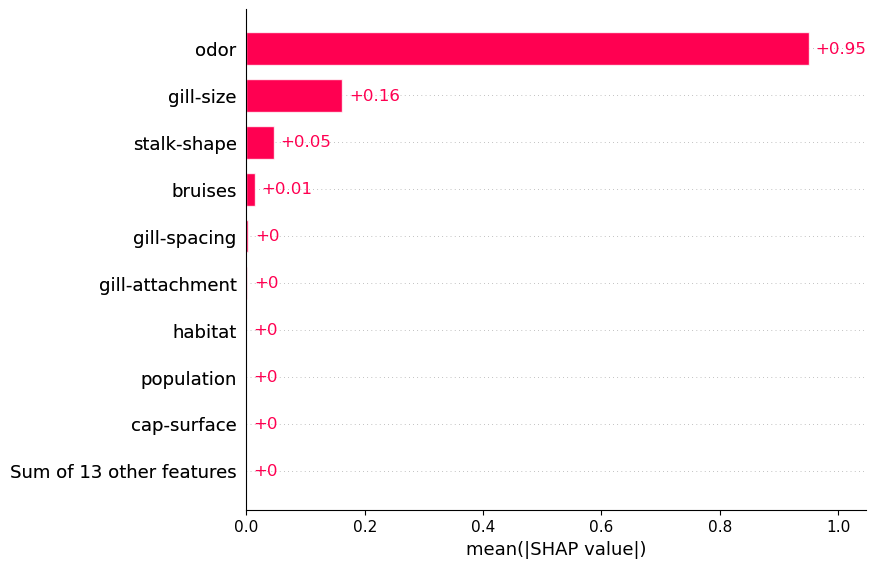
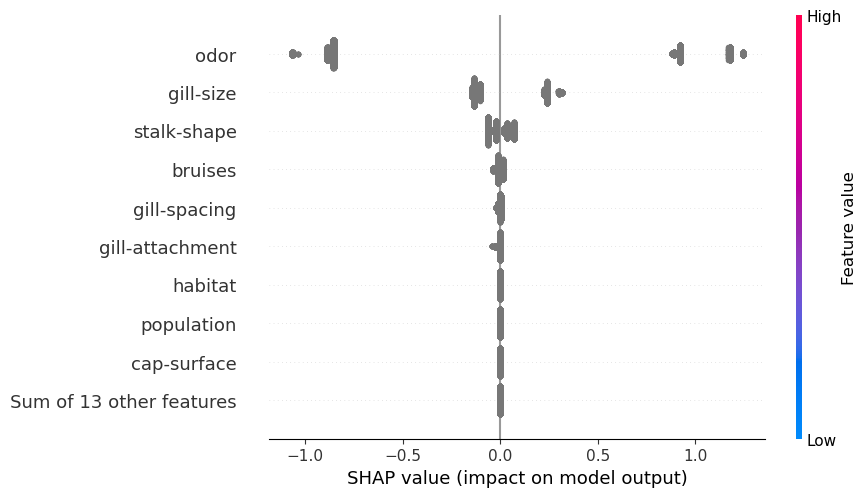
SHAP 聚合也适用于 CatBoost。例如,我们在下面的代码中使用平均 SHAP 图。查看图 5,我们可以使用此图突出显示重要的分类特征。例如,我们可以看到气味往往具有较大的正/负 SHAP 值。
1 | |
蜂群
另一种常见的聚合是蜂群图。对于连续变量,此图很有用,因为它可以帮助解释关系的性质。也就是说,我们可以看到 SHAP 值如何与特征值相关联。但是,对于分类特征,特征值不是数字。因此,在图 6 中,你可以看到 SHAP 值都被赋予了相同的颜色。我们需要创建自己的图来了解这些关系的性质。
1 | |
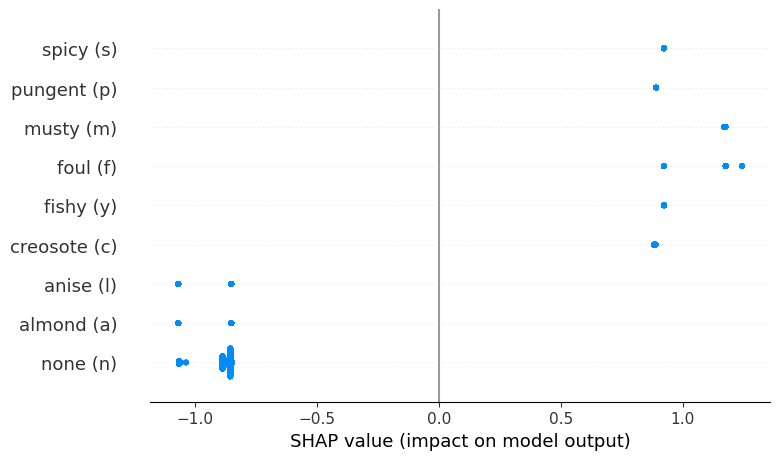
Beeswarm 的一个功能
一种方法是对单个特征使用蜂群图。你可以在图 6 中看到我们的意思。在这里,我们根据气味类别对气味特征的 SHAP 值进行了分组。例如,你可以看到难闻的气味会导致更高的 SHAP 值。这些蘑菇更有可能有毒。在上一篇文章中,我们使用箱线图得到了类似的结果。
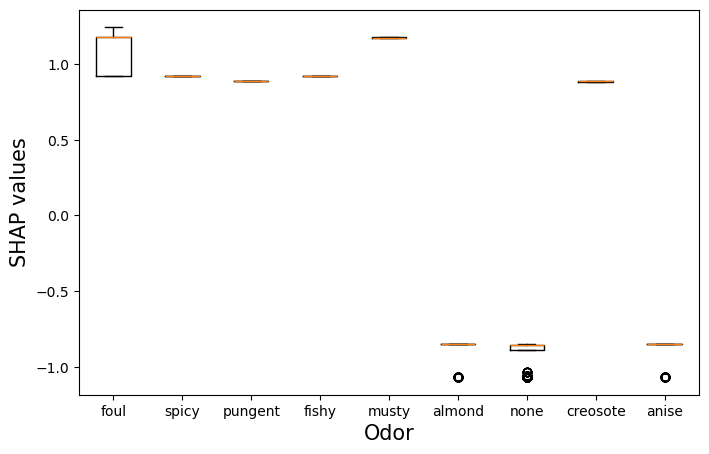
我们不会详细讨论此图的代码。简而言之,我们需要创建一个新的 SHAP
值对象 shap_values_odor。这是通过“后处理” SHAP
值来完成的,因此它们处于我们想要的形式。我们用气味的 SHAP 值替换原始
SHAP 值(第 24 行)。我们还用气味类别替换特征名称(第 43
行)。如果我们正确创建了 shap_values_odor,我们可以使用
beeswarm 函数来创建图(第 46 行)。
1 | |
最后,SHAP 和 CatBoost 是分析分类特征的强大工具。这两个软件包可以无缝协作。缺点是你可能不想使用 CatBoost。如果你正在使用 RandomForest、XGBoost 或神经网络等模型,则需要使用替代解决方案。你可以在文章分类特征的 SHAP中找到它。我们还将更详细地介绍如何对 SHAP 值进行后处理。
希望这篇文章对你有所帮助!如果你想了解更多,可以关注「坍缩的奇点」,阅读我更多其他文章。以下为一些系列文章,你可以系统的学习机器学习的相关核心知识。
「AI秘籍」系列课程:

参考
S. Lundberg, SHAP Python package (2021), https://github.com/slundberg/shap
S. Lundberg & S. Lee, A Unified Approach to Interpreting Model Predictions (2017), https://arxiv.org/pdf/1705.07874.pdf
使用 CatBoost 实现分类特征的 SHAP

